MIRIAD uses the term `dataset' to refer to an image, a cube or a set of visibilty data. A MIRIAD dataset is made from a host-system directory, i.e., the host operating system sees a `directory' whenever MIRIAD sees a `dataset'. A MIRIAD dataset contains several kinds of data, called `items', used by the MIRIAD tasks. Items can be quite small (e.g. a single number), intermediate in size (e.g. the history item, use to store history information), or very large (e.g. the image item in an image dataset, which is used to store the pixel data, or the visdata item in a visibility dataset, which contains most of the data). Large items are stored as a host system file, whereas all small items are stored in a common file which is rather inappropriately called header. Indeed, there are a number of instances where the word ``header'' is used where ``item'' or ``small item'' would be a more appropriate description.
The implementation of datasets as directories does complicate
some manipulations of your datasets, since your favourite image, etc, is not
just a file anymore.
On the other hand, as the host system sees a MIRIAD
dataset as a normal
directory, all the
usual host commands to manipulate directories can be used. On UNIX a -r
switch often has to be used with the command, to indicate that the operation
is to be applied `recursively' (i.e. to all files in the directory). For
example, to delete a dataset, use
% rm -r dataset
If you have aliased rm to prompt you before deleing a file (as is common in a number of the standard login scripts at Epping), you will be prompted before deleting each individual file within a dataset. This can become somewhat tedious, so you might want to make another alias to delete without prompting. For example, insert
alias rrm 'rm'in your .cshrc file. Similarly to copy a dataset, you would use
% cp -r dataset1 dataset2
Generally the user is insulated from this internal organization of a dataset and can always think of them as a whole. However there are a few MIRIAD utilities to manipulate at the item level. These MIRIAD tasks do not contain any astronomical knowledge. Consequently they may seem somewhat crude. Some of these commands are:
As an example, consider the itemize task, which lists the items in a dataset. For the test image dataset, gauss (created with imgen in Chapter 2) itemize will tell us of the following items:
% itemize in=gauss Itemize: version 1.1 4-mar-91 naxis = 2 naxis1 = 256 naxis2 = 256 crpix1 = 129 crpix2 = 129 cdelt1 = -4.848137e-06 cdelt2 = 4.848137e-06 crval1 = 0 crval2 = 0 history (text data, 38 elements) image (real data, 65536 elements)Here the item naxis consists of a single integer, having the value of 2. The item image is a larger item (being the pixel data) consisting of 65536 (
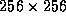 ) real numbers.
) real numbers.
Note for images that many items have FITS-like names (although they are lower case, and the units can be different from the FITS standard). A list of the items in an image and visibility dataset are given in Appendices B and C.
The task prthd provides a higher level (astronomical) summary of a dataset. For visibility datasets, it will tell you the number of visibilities, the number of spectral-channels, the number of spectral-windows (IFs), the polarisations present and some information about frequencies. Note that if the visibility dataset contains multiple source or frequencies, it will only give you information about the source and frequency of the first record. For images, it will give dimension and axis information, minimum and maximum, etc. The input to prthd is the dataset name via the keyword in. Task prthd has a brief mode, where it lists a single line description of a dataset. This is useful for generating a summary of directory contents (note that the in keyword supports wildcards).