The Karma data format is generally meant to be hidden from the programmer. More friendly interfaces such as Intelligent Arrays provide easy ways to create and manipulate multidimensional data arrays. This chapter is aimed at people who are developing interfaces between Karma and another package. One of the great strengths of Karma is that you don't have to be taken over completely just because you want to use a few bits of it. While Karma does provide a complete working environment, unlike some other large packages it does not insist that you immerse yourself in it.
Many people are justifably only interested in the Karma graphics and widget libraries, since they already have an environment in which to manipulate data. An example of this is perlDL (Perl Data Language), originally developed by Karl Glazebrook (kgb@aaoepp.aao.gov.au) and has attracted a strong following. The perlDL environment provides powerful array manipulation in an interactive environment, but lacks a built-in data display facility (it does contain modules to send data to image display tools like SAOimage or Karma visualisation tools). In such an environment, it is desirable to be able to use the Karma graphics and widget libraries directly from within the intepreter, without loosing control to Karma.
The Karma data format may be thought of as a mechanism to describe the way data is stored in virtual memory. Naturally, functions are provided to translate between virtual memory data and permanent storage and to move data between different computers, although these functions are probably not of interest unless you want to specifically write or read in Karma format. This chapter will discuss the virtual memory layout of Karma data structures.
This section gives an overview of the Karma data structure and introduces some of the terms and concepts.
The fundamental building block for Karma data is the the element. An element may fall into one of two classes: either named or unnamed elements. Unnamed elements are references to other Karma data structures, such as multi-dimensional arrays or linked lists. Named elements are further subclassed into atomic and non-atomic elements. Atomic elements include the basic C language datatypes (such as float, int, double and so on) as well as complex versions of C datatypes (the real and imaginary components are adjacent in memory, with the real component residing in lower memory). Non-atomic datatypes are somewhat more complicated datatypes such as variable-length strings or fixed-length strings. See Figure B.1 for a class heirarchy of elements.
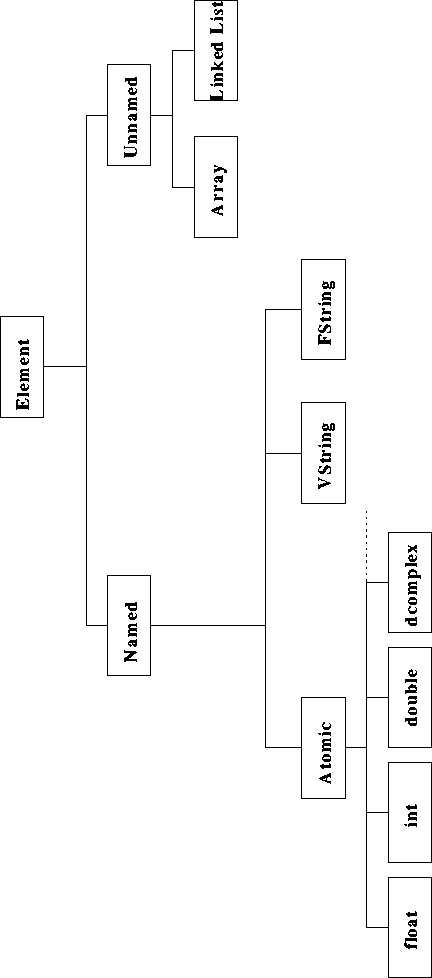
Figure B.1: Element Class Heirarchy
Elements have descriptors associated with them which are used to partly describe them. For a named element, the descriptor is simply a string which contains the name. For unnamed elements, the descriptor is either an array descriptor (for elements which point to an array), or a linked list (packet) descriptor (for elements which point to a linked list).
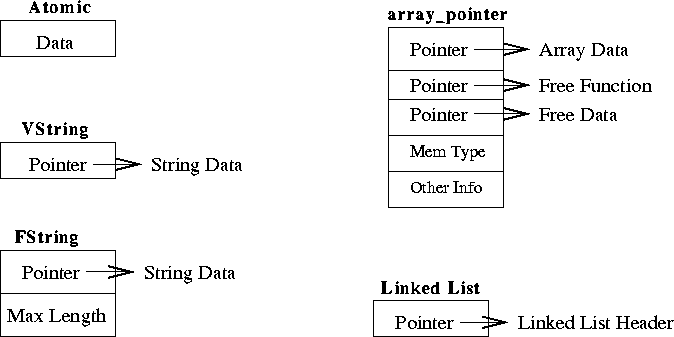
The element data for an atomic element is the memory storage for the data itself. For variable-length strings the element data is a pointer to the string. For fixed-length string the element data is a FString structure. For array pointers the data is a structure containing a pointer to the start of the array and other information. For list pointers the data is a pointer to a linked list header. See Figure B.2.
The recursive nature of the Karma data structure is due to the use of packets. A packet is a contiguous block of one or more elements, with no padding between the elements. The elements in a packet may be of any type.
Karma supports multi-dimensional arrays of packets. Because the arrays are composed of packets rather than atomic elements, it is possible to create data structures which are arrays of linked lists, or arrays with subarrays. Building a heirarchical data structure like this allows you to place data at many levels, for instance, a three-dimensional array which is structured as a one-dimensional array of packets, with each packet containing an atomic element (perhaps a scaling factor) and a pointer to a two-dimensional array. Such a structure allows you to define varying scaling factors for an array. There is no limit to the complexity you can create.
In practice, most array packets have only one atomic element, since that is the kind of data most people have. Sometimes arrays have three elements: ``Red Intensity'', ``Green Intensity'' and ``Blue Intensity'' (for TrueColour or so-called ``24bit'' images), but this is about as complicated it gets.
An array descriptor describes the construction of a multi-dimensional array of packets. As well as containing a pointer to a packet descriptor, it also contains an array of pointers to dimension descriptors. Array descriptors also provide a field into which address offset arrays may be placed. These are usually created by the ds_compute_array_offsets function. The array descriptor also provides for describing a tiling mechanism. A tiling level of 0 indicates the array is untiled.
A dimension descriptor describes a dimension in an array. It contains a length field, a name field (all dimensions are uniquely named) as well as world co-ordinate information. By default, co-ordinates are linear, so all that is needed to describe the co-ordinate system for the dimension is the co-ordinate for the first index along the dimension and the co-ordinate for the last index. A non-linear co-ordinate system with separable co-ordinates is supported by providing a co-ordinate array. The only restriction on the co-ordinates in a co-ordinate array is that they are either monotonically increasing or decreasing. Random co-ordinates are not supported. Furthermore, in co-ordinate systems where the dimensions are not seperable (such as most projections of the astronomical RA,DEC co-ordinate system), the co-ordinate system supported by dimension descriptors is insufficient. For these co-ordinate systems a separate mechanism is supplied via the wcs package.
The element data for a multi-dimensional array consists of a pointer to the start of the array data, a function to call when the array data is to be freed, and an arbitrary pointer to pass to the free function. This allows enormous flexibility in allocation/deallocation strategies, without the need for explicit support from within the Karma library. Routines such as as ds_easy_alloc_array_desc and ds_easy_alloc_array_from_array_desc may be used to ``wrap'' an externally allocated array when you fill an array_pointer structure yourself. You can even allocate data in shared memory, either using the ds_alloc_shm_array function, or filling in an array_pointer structure yourself. Figure B.2 shows the element data for an array.
Karma also provides a doubly-linked list mechanism. Linked lists are convenient when you will be periodically adding data and don't know beforehand how much data you will end up with. Karma linked lists are simply linked lists of packets.
Since a linked list is just a list of packets, the descriptor for a linked list is an ordinary packet descriptor.
The element data for a linked list is a pointer to a linked list header. This header contains fields indicating the length of the list, how the list has been sorted and fields referring to the list data. The data for a linked list comes in two parts: a contiguous and a fragmented section. The contiguous section is a contiguous block of list packets, and comes logically ``before'' the fragmented section. The rest of the list data is kept in a conventional doubly-linked list structure, with the list header containing a pointer to the first and last entries in the fragmented list. The reason for supporting the arrangement of data in these two ways is to save virtual memory space as well as performance. When a Karma file is read into virtual memory, it is already known how long the list will be, so a contiguous block of entries is allocated. It is much faster to allocate a single large block of virtual memory than to allocate a large number of small blocks. In some cases it is more convenient to deal with a contiguous block of data, and other cases it is more convenient to deal with a doubly-linked (fragmented) list. The ds_list_unfragment and ds_list_fragment functions allow you to convert a list to either form.
The recursive nature of the Karma data structure may leave you wondering where it all starts? Part of the answer is the General Data Structure, which is a top-level packet descriptor and its matching (single) packet. Karma imposes the restriction that all names (i.e. dimension names and element names for named elements) in a General Data Structure are unique.
It is possible to create a General Data Structure which has two (or more) elements in its top-level packet, each which is an array pointer. You could have two arrays, with possibly different shapes, in a single General Data Structure. More commonly, you may want to have a top-level packet with a single array pointer but with many named elements. This is a simple way of describing FITS-style data: the array corresponds to the FITS array and the named elements correspond to the FITS keywords.
The highest level in the Karma data structure is provided by the multi_array structure. This supports one or more General Data Structures (sometimes confusingly referred to as arrays). In the case where the multi_array contains more than one General Data Structure, each is uniquely named. The namespace for each General Data Structure is separate. The multi_array structure provides a mechanism to package several data structures together into a single file. This is typically used to package a colourtable together with a multi-dimensional array.
The multi_array structure also provides the means to manage the creation, use and destruction of data structures. Packages like the iarray package will increment the attachment counter on a multi_array structure when they create their own ``view'' into the data. Every time the ds_dealloc_multi function is called, the attachment count is decremented. Only when it reaches 0 is the data structure destroyed. The other mechanism provided by the ds package is a list of destroy callbacks attached to the multi_array structure. This is another way to manage data structures which are a view into the multi_array data, but in a more self-contained way (perhaps used in the internals of a widget). In most cases, the attachment mechanism is more convenient, since it does not require you to deal with cleaning up properly when a multi_array data structure is destroyed: data is only destroyed when nobody is interested in it any more.
Finally, the multi_array structure contains a mechanism to record ``history'' information. These are just human-readable comments that are appended to a file which describe how the data has been processed. The history is usually manipulated with the ds_history_append_string function.
This section discusses how to create your own Karma data structure, or how you might wrap your own data structure in a Karma data structure. Wrapping your own data structure is basically a matter of creating the correct Karma data structure descriptors: it doesn't affect your data, but it does allow you to use Karma functions to use and manipulate your data.
The simplest interface available is the ds_easy_alloc_array function. This will create a multi-dimensional array of uni-variate data (i.e. an ordinary array where each point in the array contains a single value). This function yields a pointer to the beginning of the array and a handle to a multi_array descriptor. This interface is not commonly used outside the Karma environment, since the iarray package provides a much simpler and more powerful interface for creation and manipulation of multi-dimensional data. The array is allocated from ordinary virtual memory.
If you wanted to create an array using shared memory, you need to make a few function calls. While slightly more complicated, the advantage of shared memory is that if you subsequently transmit the array to another process on the same computer using Karma connections, the array data does not actually need to be transferred. What happens is that the destination process receives a handle to the same array data. This makes the cost of transferring array data essentially zero. Karma also supports auto-creation of files which are then memory mapped as an alternative mechanism for sharing arrays between processes. The following code first attempts to create a SysV shared memory array (by calling ds_alloc_shm_array) and if that fails it attempts to create a memory mapped file (by calling ds_alloc_mmap_array).
Below is some sample code which creates a two-dimensional array (128x128) of floating-point data in shared memory and then obtains the pointer to the start of the array data. Error checking has been omitted in order to aid clarity.
unsigned int type K_FLOAT;
char *array;
array_pointer arrayp;
array_desc *arr_desc;
multi_array *multi_desc;
uaddr lengths[2];
CONST char *elem_name = "Data Value";
lengths[0] = 128;
lengths[1] = 128;
arr_desc = ds_easy_alloc_array_desc (2, lengths, NULL, NULL, NULL,
NULL, 1, &type, &elem_name);
if ( !ds_alloc_shm_array (&arrayp, arr_desc, TRUE, TRUE) &&
!ds_alloc_mmap_array (-1, 0, 0, TRUE, &arrayp, arr_desc, TRUE, TRUE) )
exit (1);
multi_desc = ds_easy_alloc_array_from_array_desc (arr_desc, &arrayp);
array = arrayp.array;
In the following example the code falls back to ordinary virtual memory if the shared memory allocation failed. Once again error checking has been omitted for the sake of clarity.
unsigned int type K_FLOAT;
char *array;
array_pointer arrayp;
array_desc *arr_desc;
multi_array *multi_desc;
uaddr lengths[2];
CONST char *elem_name = "Data Value";
lengths[0] = 128;
lengths[1] = 128;
arr_desc = ds_easy_alloc_array_desc (2, lengths, NULL, NULL, NULL,
NULL, 1, &type, &elem_name);
if ( !ds_alloc_shm_array (&arrayp, arr_desc, TRUE, FALSE) &&
!ds_alloc_mmap_array (-1, 0, 0, TRUE, &arrayp, arr_desc, TRUE, FALSE) &&
!ds_alloc_vm_array (&arrayp, arr_desc, TRUE, FALSE) )
exit (2);
multi_desc = ds_easy_alloc_array_from_array_desc (arr_desc, &arrayp);
array = arrayp.array;
Here you can see that if the shared memory or memory mapped allocation fails, the ds_alloc_vm_array function is called to allocate ordinary virtual memory.
If you had your own array of data that you wanted to wrap in a Karma data structure, you would probably use the ds_wrap_preallocated_n_element_array which will take a pointer to your data and creates a multi_array descriptor. Of course, you have to supply some extra parameters to describe how your data is arranged. This function assumes that the data is contained in ordinary virtual memory. Note that it would be quite valid to use this function for an array which resides in shared memory, but then Karma would not know this and not be able to take advantage of this. In which case there probably wasn't any point to creating a shared memory array in the first place.
This is similar to the example of creating an array in shared memory (above), but instead of making a call to ds_alloc_shm_array you would need to fill in the contents of an array_pointer structure yourself. You should look at the Karma header files for the definition of this structure, as well as the magic constants. The structure definition is fully commented, so it should be clear what you need to do. A code extract from the ds_alloc_shm_array function at the time of writing is given below.
arrayp->array = addr; arrayp->free = ( void (*) (void *) ) m_shm_detach; arrayp->info = addr; arrayp->mem_type = K_ARRAY_MEM_TYPE_SHM; arrayp->u.shm.shmid = shmid; arrayp->u.shm.base = addr;
Here the addr variable contains the pointer to the start of the shared memory segment and the shmid variable contains the shared memory ID. Note how the free member function is defined: this will be called when the Karma data structure is deallocated. You may substitute your own function here, or write a NULL to indicate that no action should be taken to deallocate the shared memory. This gives you complete flexibility in allocating and deallocating array data.
This is similar to the example of creating an array in mapped memory (above), but instead of making a call to ds_alloc_mmap_array you would need to fill in the contents of an array_pointer structure yourself. A code extract from the ds_alloc_mmap_array function at the time of writing is given below.
arrayp->array = addr; arrayp->mem_type = K_ARRAY_MEM_TYPE_MMAP; arrayp->u.mmap.fd = fd; arrayp->u.mmap.size = size; arrayp->u.mmap.base = addr;
Here the addr variable contains the pointer to the start of the mapped file, the fd variable is the open file and the size variable is the size of the mapped region (this may be larger than the actual array storage requirements).