
This chapter looks at how interrupts are handled by the Linux kernel. Whilst the kernel has generic mechanisms and interfaces for handling interrupts, most of the interrupt handling details are architecture specific.
This chapter looks at how interrupts are handled by the Linux kernel.
Whilst the kernel has generic mechanisms and interfaces for handling
interrupts, most of the interrupt handling details are architecture specific.
Linux uses a lot of different pieces of hardware to perform many different tasks. The video device drives the monitor, the IDE device drives the disks and so on. You could drive these devices synchronously, that is you could send a request for some operation (say writing a block of memory out to disk) and then wait for the operation to complete. That method, although it would work, is very inefficient and the operating system would spend a lot of time ``busy doing nothing'' as it waited for each operation to complete. A better, more efficient, way is to make the request and then do other, more useful work and later be interrupted by the device when it has finished the request. With this scheme, there may be many outstanding requests to the devices in the system all happening at the same time.
There has to be some hardware support for the devices to interrupt whatever the CPU is doing. Most, if not all, general purpose processors such as the Alpha AXP use a similar method. Some of the physical pins of the CPU are wired such that changing the voltage (for example changing it from +5v to -5v) causes the CPU to stop what it is doing and to start executing special code to handle the interruption; the interrupt handling code. One of these pins might be connected to an interval timer and receive an interrupt every 1000th of a second, others may be connected to the other devices in the system, such as the SCSI controller.
Systems often use an interrupt controller to group the device interrupts together before passing on the signal to a single interrupt pin on the CPU. This saves interrupt pins on the CPU and also gives flexibility when designing systems. The interrupt controller has mask and status registers that control the interrupts. Setting the bits in the mask register enables and disables interrupts and the status register returns the currently active interrupts in the system.
Some of the interrupts in the system may be hard-wired, for example, the real time clock's interval timer may be permanently connected to pin 3 on the interrupt controller. However, what some of the pins are connected to may be determined by what controller card is plugged into a particular ISA or PCI slot. For example, pin 4 on the interrupt controller may be connected to PCI slot number 0 which might one day have an ethernet card in it but the next have a SCSI controller in it. The bottom line is that each system has its own interrupt routing mechanisms and the operating system must be flexible enough to cope.
Most modern general purpose microprocessors handle the interrupts the same way. When a hardware interrupt occurs the CPU stops executing the instructions that it was executing and jumps to a location in memory that either contains the interrupt handling code or an instruction branching to the interrupt handling code. This code usually operates in a special mode for the CPU, interrupt mode, and, normally, no other interrupts can happen in this mode. There are exceptions though; some CPUs rank the interrupts in priority and higher level interrupts may happen. This means that the first level interrupt handling code must be very carefully written and it often has its own stack, which it uses to store the CPU's execution state (all of the CPU's normal registers and context) before it goes off and handles the interrupt. Some CPUs have a special set of registers that only exist in interrupt mode, and the interrupt code can use these registers to do most of the context saving it needs to do.
When the interrupt has been handled, the CPU's state is restored and the interrupt is dismissed. The CPU will then continue to doing whatever it was doing before being interrupted. It is important that the interrupt processing code is as efficient as possible and that the operating system does not block interrupts too often or for too long.
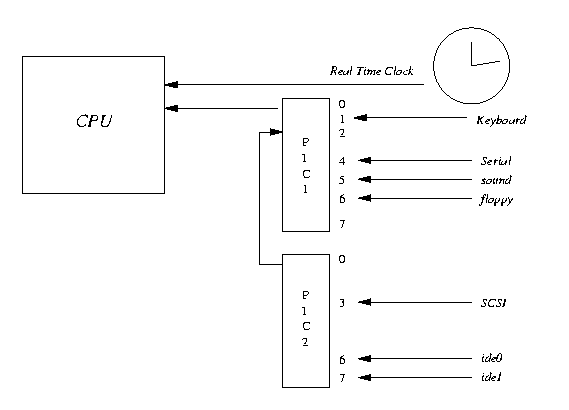
Systems designers are free to use whatever interrupt architecture they wish but IBM PCs use the Intel 82C59A-2 CMOS Programmable Interrupt Controller or its derivatives. This controller has been around since the dawn of the PC and it is programmable with its registers being at well known locations in the ISA address space. Even very modern support logic chip sets keep equivalent registers in the same place in ISA memory. Non-Intel based systems such as Alpha AXP based PCs are free from these architectural constraints and so often use different interrupt controllers.
Figure 7.1 shows that there are two 8 bit controllers chained together; each having a mask and an interrupt status register, PIC1 and PIC2. The mask registers are at addresses 0x21 and 0xA1 and the status registers are at 0x20 and 0xA0 Writing a one to a particular bit of the mask register enables an interrupt, writing a zero disables it. So, writing one to bit 3 would enable interrupt 3, writing zero would disable it. Unfortunately (and irritatingly), the interrupt mask registers are write only, you cannot read back the value that you wrote. This means that Linux must keep a local copy of what it has set the mask registers to. It modifies these saved masks in the interrupt enable and disable routines and writes the full masks to the registers every time.
When an interrupt is signalled, the interrupt handling code reads the two interrupt status registers (ISRs). It treats the ISR at 0x20 as the bottom eight bits of a sixteen bit interrupt register and the ISR at 0xA0 as the top eight bits. So, an interrupt on bit 1 of the ISR at 0xA0 would be treated as system interrupt 9. Bit 2 of PIC1 is not available as this is used to chain interrupts from PIC2, any interrupt on PIC2 results in bit 2 of PIC1 being set.
The individual device drivers call these routines to register their interrupt handling routine addresses.
Some interrupts are fixed by convention for the PC architecture and so the driver simply requests its interrupt when it is initialized. This is what the floppy disk device driver does; it always requests IRQ 6. There may be occassions when a device driver does not know which interrupt the device will use. This is not a problem for PCI device drivers as they always know what their interrupt number is. Unfortunately there is no easy way for ISA device drivers to find their interrupt number. Linux solves this problem by allowing device drivers to probe for their interrupts.
First, the device driver does something to the device that causes it to interrupt. Then all of the unassigned interrupts in the system are enabled. This means that the device's pending interrupt will now be delivered via the programmable interrupt controller. Linux reads the interrupt status register and returns its contents to the device driver. A non-zero result means that one or more interrupts occured during the probe. The driver now turns probing off and the unassigned interrupts are all disabled.
If the ISA device driver has successfully found its IRQ number then it can now request control of it as normal.
PCI based systems are much more dynamic than ISA based systems. The interrupt pin that an ISA device uses is often set using jumpers on the hardware device and fixed in the device driver. On the other hand, PCI devices have their interrupts allocated by the PCI BIOS or the PCI subsystem as PCI is initialized when the system boots. Each PCI device may use one of four interrupt pins, A, B, C or D. This was fixed when the device was built and most devices default to interrupt on pin A. The PCI interrupt lines A, B, C and D for each PCI slot are routed to the interrupt controller. So, Pin A from PCI slot 4 might be routed to pin 6 of the interrupt controller, pin B of PCI slot 4 to pin 7 of the interrupt controller and so on.
How the PCI interrupts are routed is entirely system specific and there must be some set up code which understands this PCI interrupt routing topology. On Intel based PCs this is the system BIOS code that runs at boot time but for system's without BIOS (for example Alpha AXP based systems) the Linux kernel does this setup.
The PCI set up code writes the pin number of the interrupt controller into the PCI configuration header for each device. It determines the interrupt pin (or IRQ) number using its knowledge of the PCI interrupt routing topology together with the devices PCI slot number and which PCI interrupt pin that it is using. The interrupt pin that a device uses is fixed and is kept in a field in the PCI configuration header for this device. It writes this information into the interrupt line field that is reserved for this purpose. When the device driver runs, it reads this information and uses it to request control of the interrupt from the Linux kernel.
There may be many PCI interrupt sources in the system, for example when PCI-PCI bridges are used. The number of interrupt sources may exceed the number of pins on the system's programmable interrupt controllers. In this case, PCI devices may share interrupts, one pin on the interrupt controller taking interrupts from more than one PCI device. Linux supports this by allowing the first requestor of an interrupt source declare whether it may be shared. Sharing interrupts results in several irqaction data structures being pointed at by one entry in the irq_action vector vector. When a shared interrupt happens, Linux will call all of the interrupt handlers for that source. Any device driver that can share interrupts (which should be all PCI device drivers) must be prepared to have its interrupt handler called when there is no interrupt to be serviced.
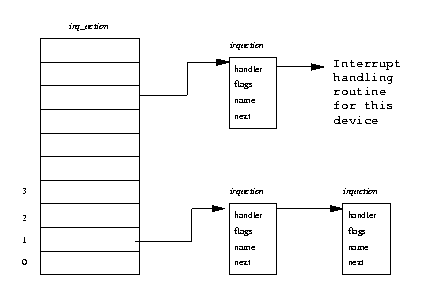
One of the principal tasks of Linux's interrupt handling subsystem is to route the interrupts to the right pieces of interrupt handling code. This code must understand the interrupt topology of the system. If, for example, the floppy controller interrupts on pin 6 1 of the interrupt controller then it must recognize the interrupt as from the floppy and route it to the floppy device driver's interrupt handling code. Linux uses a set of pointers to data structures containing the addresses of the routines that handle the system's interrupts. These routines belong to the device drivers for the devices in the system and it is the responsibility of each device driver to request the interrupt that it wants when the driver is initialized. Figure 7.2 shows that irq_action is a vector of pointers to the irqaction data structure. Each irqaction data structure contains information about the handler for this interrupt, including the address of the interrupt handling routine. As the number of interrupts and how they are handled varies between architectures and, sometimes, between systems, the Linux interrupt handling code is architecture specific. This means that the size of the irq_action vector vector varies depending on the number of interrupt sources that there are.
When the interrupt happens, Linux must first determine its source by reading the interrupt status register of the system's programmable interrupt controllers. It then translates that source into an offset into the irq_action vector vector. So, for example, an interrupt on pin 6 of the interrupt controller from the floppy controller would be translated into the seventh pointer in the vector of interrupt handlers. If there is not an interrupt handler for the interrupt that occurred then the Linux kernel will log an error, otherwise it will call into the interrupt handling routines for all of the irqaction data structures for this interrupt source.
When the device driver's interrupt handling routine is called by the Linux kernel it must efficiently work out why it was interrupted and respond. To find the cause of the interrupt the device driver would read the status register of the device that interrupted. The device may be reporting an error or that a requested operation has completed. For example the floppy controller may be reporting that it has completed the positioning of the floppy's read head over the correct sector on the floppy disk. Once the reason for the interrupt has been determined, the device driver may need to do more work. If it does, the Linux kernel has mechanisms that allow it to postpone that work until later. This avoids the CPU spending too much time in interrupt mode. See the Device Driver chapter (Chapter dd-chapter) for more details.
REVIEW NOTE: Fast and slow interrupts, are these an Intel thing?
1 Actually, the floppy controller is one of the fixed interrupts in a PC system as, by convention, the floppy controller is always wired to interrupt 6.