3 Conformance: Requirements and Recommendations
3.1 Definitions
In this section, we begin the formal specification of CSS2,
starting with the contract between authors, documents, users, and user
agents.
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT",
"SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this
document are to be interpreted as described in [RFC2119]. However, for
readability, these words do not appear in all upper case letters in
this specification.
At times, the authors of this specification recommend good practice
for authors and user agents. These recommendations are not normative
and conformance with this specification does not depend on their
realization. These recommendations contain the expression "We
recommend ...", "This specification recommends ...", or some similar
wording.
- Style sheet
- A set of statements that specify
presentation of a document.
Style sheets may have three different origins: author, user, and user agent. The interaction of these sources is
described in the section on cascading and
inheritance.
- Valid style sheet
- The validity
of a style sheet depends on the level of CSS used for the style sheet.
All valid level N-1 style sheets are valid level N style sheets. In
particular, all valid CSS1 style sheets are valid CSS2 style sheets.
A valid CSS2 style sheet must respect the grammar of CSS2 and the selector syntax. Furthermore, it must only
contain at-rules, property names, and property values defined in this
specification.
- Source document
- The document to which one or more style sheets refer.
- Document language
- The computer language of the source
document (e.g., HTML, XML, etc.).
The primary syntactic constructs of the document language are
called elements, (an SGML term, see [ISO8879]). Most CSS style sheet rules refer to
these elements and specify rendering information for them. Examples
of elements in HTML include "P" (for structuring paragraphs), "TABLE"
(for creating tables), "OL" (for creating ordered lists), etc.
The content of an element is
the content of that element in the source document; not all elements
have content. The rendered
content of an element is the content actually
rendered. An element's content is generally its rendered content. The
rendered content of a replaced
element comes from outside the source document.
Rendered content may also be alternate text
for an element (e.g., the value of the HTML "alt" attribute).
- Document tree
- User agents transform a document written in the document language
into a document tree where every element except one has
exactly one parent
element. (See the SGML ([ISO8879]) and XML ([XML]) specifications for the definition of
parent.) The one exception is the root element, which has no parent.
An element A is called an ancestor of an element B, if either
(1) A is the parent B, or (2) A is the parent of some element C that
is an ancestor of B.
An element A is called a descendant of an element B, if
and only if B is an ancestor of A. An element A is called a child of an element B, if and
only if B is the parent of A.
An element A is called a sibling of an element B, if and only
if B and A share the same parent element. Element A is a preceding
sibling if it comes before B in the document tree. Element B is a
following sibling if it comes after B in the document tree.
An element A is called a preceding element
of an element B, if and only if (1) A is an ancestor of B or (2) A is
a preceding sibling of B. An element A is called a following element of an element
B, if and only if (1) A is an descendant of B or (2) A is a following
sibling of B.
For example, the following HTML document:
<HTML>
<TITLE>My home page</TITLE>
<BODY>
<H1>My home page</H1>
<P>Welcome to my home page! Let me tell you about my favorite
composers:
<UL>
<LI> Elvis Costello
<LI> Johannes Brahms
<LI> Georges Brassens
</UL>
</BODY>
</HTML>
results in the following tree:
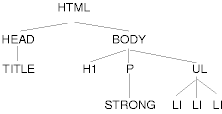
According to the definition of HTML, HEAD elements will be inferred
during parsing and become part of the document tree even if the HEAD
tags are not in the document source.
- Author
- An author is a person or program that
writes or generates style sheets.
- User
- A user is a person who interacts with a user agent to view, hear,
or otherwise use a document and its associated style sheets.
- User agent
- A user
agent is any program that interprets a document written in
the document language and applies associated style sheets according
to the terms of this specification. A user agent may display a
document, read it aloud, cause it to be printed, convert it
to another format, etc.
This section defines conformance with the CSS2
specification only. There may be other levels of CSS in the future
that may require a user agent to implement a different set of features
in order to conform.
In general, the following points must be observed by user agents
claiming conformance to this specification:
- It must identify the CSS2 media types it
supports.
- For each source document, it must retrieve all
associated style sheets that are appropriate for the supported media
types. If a user agent cannot retrieve a specified style sheet,
it should make a best effort to display the document.
- It must parse the style sheets according to this specification.
In particular, it must recognize all at-rules, blocks, declarations,
and selectors (see the grammar of CSS2).
If a user agent encounters a property that applies for a supported
media type, the user agent must parse the value according to the property
definition. This means that the user agent must accept all legal
values and must
skip other values. User
agents must skip
rules that apply to unsupported media
types.
- Given a document tree, it must
assign a value for every supported property according to
the rules of cascading and inheritance.
Not every user agent must observe every point, however:
- A user agent that inputs style sheets must
respect points 1 - 3.
- A user agent that outputs style sheets is only required
to output valid style sheets
- A user agent that renders a document with associated style
sheets must respect points 1 - 4 and render the document
according to the media-specific requirements set forth in this
specification.
The inability of a user agent to implement part of this
specification due to the limitations of a particular device (e.g., a
user agent cannot render colors on a monochrome monitor or page) does
not imply non-conformance.
This specification also recommends that a user agent offer the following
functionality to the user (these do not refer to any specific
user interface):
- Allow the user to specify user style sheets
- Allow the user to turn on or off specific style sheets .
- Approximate style sheet values even if it can't implement
them in strict accordance with this specification.
3.3 Error conditions
In general, this document does not specify error handling behavior
for user agents.
However, user agents must observe the rules for handling parsing errors.
Since user agents may vary in how they handle error conditions,
authors and users must not rely on specific error recovery behavior.